Implementations Patterns, de Kent Beck, es un libro sobre programación que define buenas prácticas a seguir en el desarrollo de código en Java, con el objetivo de tener un código legible y del que nos sintamos orgullosos. Se busca mejorar la perspectiva que tenga un programador sobre el sistema que va a tratar, para que entienda que cuando escriba código, éste debe hablar por si solo, debe ser la respuesta correcta y simple a una pregunta que se haga una persona cuando debe resolver un problema. Podemos decir entonces que el libro trata la responsabilidad que debe asumir un programador para tener un código satisfactorio.
La programación va más allá de la comunicación del hombre con la máquina, el programador debe pensar que su trabajo lo van a ver otras personas que tendrán que interpretar su código, así mismo como puede ser el mismo quien vea su propio trabajo en un futuro. Para lograr que todo ésta interpretación no sea un tormento, deberíamos tener patrones que definan como desarrollamos código simple y eficaz.
PATRONES
Todo programador debería conocer/seguir un conjunto de leyes que de cumplir sus programas como son:
- La mayor parte del tiempo se dedica a leer, más que a escribir.
- Nunca hay un “terminé”. Se invierte más en modificaciones que en el desarrollo inicial.
- Se estructuran utilizando un conjunto básico de conceptos de flujo de estado y control.
- Los lectores necesitan entender los programas en detalle y en concepto.
Los patrones tienden un puente entre los principios abstractos y la práctica. Además buscan ahorrar tiempo y energía, ya que se establecen para simplificar enormemente una tarea. Nos ayudan a abordar la toma de decisiones en un problema real. Entonces, los patrones de implementación nos ayudan a escribir soluciones razonables para problemas comunes en la programación.
Hay que entender que por muchos problemas que cubramos con patrones no podremos cubrir todas las situaciones que surjan en el desarrollo. Tener una lista de patrones es simplemente una teoría que se adapta a cada situación y necesidad.
UNA TEORÍA DE LA PROGRAMACIÓN
Los valores proporcionan motivación, los principios traducen esa motivación en acción, y finalmente son los patrones los que describen como se va a hacer. El estilo de desarrollo de cada programador viene definido a partir de sus valores personales y de los principios que expresen sus patrones de implementación.
Tres valores fundamentales son la comunicación(un lector puede entenderlo), la simplicidad(eliminar el exceso de complejidad) y la flexibilidad(la forma en que cambian)
Los principios son ideas más específicas de la programación, y son la base de los patrones, ya que son los que explican el por qué se ha desarrollado determinado patrón.
Las consecuencias locales definen que si un cambio aquí puede causar un problema allá , entonces el costo del cambio aumenta dramáticamente. El código con consecuencias mayormente locales se comunica de manera efectiva.
Cuando se tiene el mismo código en varios lugares, si se cambia una copia del código hay que decidir si se cambian o no todas las demás copias. Su cambio ya no es local. Cuantas más copias del código, más costará el cambio.
Otro razonamiento del principio de las consecuencias locales es mantener la lógica y los datos juntos. Poner la lógica y los datos sobre los que opera cerca el uno del otro, en el mismo método si es posible, o en el mismo objeto, o al menos en el mismo paquete.
La simetría en el código es donde la misma idea se expresa de la misma manera en todos los lugares donde aparece en el código. En el siguiente ejemplo la segunda afirmación es más concreta que las demás, por lo que debemos llevarla al mismo nivel de abstración.
*/*BEFORE*/*
entrada();
cuenta++;
*/*AFTER*/*
entrada();
increment();
Un último principio es poner juntos la lógica o los datos que cambian a la misma velocidad y separar la lógica o los datos que cambian a velocidades diferentes. Estas tasas de cambio son una forma de simetría temporal.
MOTIVATION
El mantenimiento es caro porque entender el código existente lleva tiempo y es propenso a errores. Hacer cambios es generalmente fácil cuando se sabe lo que hay que cambiar. Aprender lo que hace el código actual es la parte más costosa. Una vez que los cambios se hacen, necesitan ser probados y desplegados.
Para intentar reducir el costo general debemos encontrar la forma de obtener beneficios inmediatos al tiempo que se establece un código limpio para facilitar el desarrollo futuro, reduciendo así los gastos de mantenimiento.
Es por ésto que podemos decir que es importante tener patrones de implementación que nos permitan realizar todo lo anterior de una manera rápida, que lo hagamos casi de forma automática.
CLASES
Los patrones de clase tienen mayor alcance que cualquier otro patrón de implementación. Los patrones de diseño nos hablan de las relaciones entre clases.
Usamos clases para agrupar una serie de datos y asociar una lógica a ellos. En una clase, la lógica debe cambiar de forma más lenta que como lo hacen los datos sobre los que opera. Dichos datos cambian a velocidades similares y son operados por la lógica relacionada. Una programación efectiva con objetos comprende saber agrupar la lógica en clases y representar sus variaciones en función de los datos que usa. Otro aspecto a tener en cuenta es la herencia, para poder definir múltiples variaciones de una clase padre en varias subclases.
Aunque usar clases presente grandes beneficios para la estructuración en nuestro código, debemos saber cuando usarlas y cuando no. Es decir, debemos reducir el número de clases para lograr reducir la dimensión del sistema, pero siempre y cuando se respete que las demás clases no se sobrecargan a raíz de realizar dicha reducción.
¿Como podemos comunicar nuestras intecCiones correctamente declarando las clases?. A continuación se da una serie de principios que son la respuesta a ello:
- Nombre simple de la superclase/interfaz: Un nombre correcto puede llegar a simplificar y mejorar mucho la situación. “Las clases son el el anclaje central del diseño”, lo que quiere decir que cuando creemos método lo haremos en función del nombre de la clase, por lo que ésta primera definición es crucial para las definiciones que le prosiguen. A veces necesitas seguir adelante con nuevas funciones, tiempo de confianza, frustración y tu subconsciente para proporcionar un nombre mejor.La conversación es una herramienta que me ayuda constantemente a encontrar mejores nombres. Explicar el propósito de un objeto a otra persona te lleva a encontrar mejores nombres para lo que estás describiendo.
- Nombre de la subclase: Los nombres de las subclases tienen dos trabajos. Necesitan comunicar cómo son de clase y en qué se diferencian. Una vez más, el equilibrio que se debe lograr es entre la longitud y la expresividad. Use esa superclase como base para el nombre de la subclase. Los nombres de clase que son demasiado cortos gravan la memoria a corto plazo del lector. Los grupos de clases cuyos nombres no se relacionan entre sí serán difíciles de comprender y recordar. Usen los nombres de las clases para contar la historia de su código.
- Interfaz abstracta: Se busca codificar a las interfaces, no a las implementaciones. Esta es otra forma de sugerir que una decisión de diseño no debe ser visible en más lugares de los necesarios. Si la mayor parte de mi código sólo sabe que estoy tratando con una colección soy libre de cambiar la clase concreta más tarde. Puede ser representado en Java como una interfaz o como una superclase. Pague por las interfaces sólo cuando necesite la flexibilidad que ellas crean.Otro factor económico en la introducción de las interfaces es la imprevisibilidad de los programas informáticos. Nuestra industria parece adicta a la idea de que si diseñáramos bien el software no tendríamos que cambiar nuestros sistemas.
- Interfaz: Una forma de decir “Esto es lo que quiero lograr y más allá de eso hay detalles que no deberían preocuparme” es declarar una interfaz de Java. Tienen algo de la flexibilidad de la herencia múltiple sin la complejidad y la ambigüedad. Las interfaces como clases sin implementaciones deben ser nombradas como si fueran clases. Por ejemplo, para dejar constancia de una interfaz, podríamos declarar la interfaz como “IFile”, y la clase que la implementa “File”. Abtenerse de nombres como “FileImpl”, ya que es una abreviatura.
- Clase abstracta(superclase): La otra forma de expresar la distinción entre la interfaz abstracta y la implementación concreta en Java es usar una superclase. La superclase es abstracta en el sentido de que puede ser reemplazado en tiempo de ejecución con cualquier subclase. Las interfaces abstractas necesitan soportar dos tipos de cambio: cambio en la implementación y cambio de la propia interfaz. Las interfaces de Java no soportan bien esta última. Cada cambio en una interfaz requiere cambios en todas las implementaciones. Las clases abstractas no sufren esta limitación. Siempre que se pueda especificar una implementación por defecto, se pueden añadir nuevas operaciones a una clase abstracta sin interrumpir a los implementadores existentes. Una limitación de las clases abstractas (superclase) es que los implementadores sólo pueden declarar su lealtad a una superclase. Si son necesarias otras vistas de la misma clase, deben ser implementadas por interfaces Java.
Interfaz versionada
¿Qué haces cuando necesitas cambiar una interfaz pero no puedes? Típicamente esto sucede cuando quieres añadir operaciones. Ya que añadir una operación romperá todos los implementos existentes, no puedes hacer eso. Sin embargo, puedes declarar una nueva interfaz que amplíe la interfaz original y añadir la operación allí. Los usuarios que desean la nueva funcionalidad utilizan la interfaz ampliada mientras que los usuarios existentes permanecen ajenos a la existencia de la nueva interfaz.
Value Object
Este estilo funcional de computación nunca cambia ningún estado, sólo crea nuevos valores. Cuando se tiene una situación estática (quizás momentáneamente) sobre la que se quiere hacer afirmaciones o sobre la que se quiere hacer preguntas, entonces el value object es apropiado. Cuando la situación cambia con el tiempo,entonces el estado es apropiado.
Subclase
Declarar una subclase es una forma de decir, “Estos objetos son como esos excepto…” Si tienes la superclase correcta, crear una subclase puede ser una manera poderosa de programar. Con el método correcto para anular a la superclase, puedes introducir una variante de un cálculo existente con unas pocas líneas de código. Como también tiene desventajas: si descubres que
algún conjunto de variaciones no está bien expresado como subclases, tienes que trabajar para desenmarañar el código antes de poder reestructurarlo; segundo, tienes que entender la superclase antes de que puedas entender la subclase; tercero, los cambios en una superclase son arriesgados, ya que las subclases pueden depender de propiedades sutiles de la implementación de la superclase.
Una clave para lograr subclases útiles es implementar la lógica de la superclase en métodos que hagan un solo trabajo, para facilitar la reutilización o cambio en la subclases.
ESTADO
Cuando hablamos de estado, nos referimos a esos valores que forman el estado del programa. Cuando usamos POO, éstos valores son pequeñas piezas encapsuladas en objetos, permitiéndonos así entender mejor que valor hizo cambiar el estado.
A continuación se definen una serie de patrones que afectan al estado:
- Acceso: Hay dos formas de acceder a los valores: acceso a valores almacenados e invocando cálculos. Acceder a la memoria es como invocar una función que devuelve los valores almacenados actualmente. Invocar una función es como leer un lugar de memoria, cuyo contenido simplemente se calcula y no simplemente se devuelve. Dos tipos de acceso: Acceso Directo → Cuando pasamos un dato concreto, lo cuál aporta una clara expresividad, pero pierde en flexibilidad. Acceso Indirecto → Cuando pasamos una variable y el método se encarga de realizar lo que sea necesario antes de asignar dicho dato, lo cual requiere conocer además el comportamiento de otro factor, pero ganamos en flexibilidad, pudiendo aplicar las operaciones que queramos.
- Estado común: Muchos cálculos comparten los mismos elementos de datos aunque los valores sean diferentes. Cuando encuentre un cálculo de este tipo, comuníquelo declarando los campos de una clase.
- Estado variante: Otras veces se deben tener diferentes elementos de datos, ya sea porque una clase necesita varias propiedades, en éste caso se deben declaran los campos intentando agrupar los comunes en un estado común.
- Variables: Datos almacenados que son variantes con el tiempo. Variables locales → Accesibles desde donde se declaran hasta el final del bloque.
- Recopilador: recolecta información para su uso posterior.
- Contador: una especie de recopilador que recolecta la cuenta de otros objetos.
- Explicativas: Las que su nombre son definidos para guiar al lector.
- Reutilizador: Las que se definen para ahorrar al entorno de trabajo el calculo de una variable que siempre tienen el mismo valor.
- Elementos: Las que usamos cuando queremos decir “por cada objeto en ésta lista…”.
- Campo: Los atributos que pertenecen y se declaran a un objeto.
- Ayudante: El campo definido para usar las referencias de otro objeto.
- Bandera: Los que definen como se va a usar el objeto, y que si tienen método para alterar su estado además dicen que el uso puede variar a lo largo de la ejecucción.
- Estrategia: Cuando almacenamos la parte variante que puedan tener los métodos, proporcionando métodos para que cambie.
- Estado: Son como los estratégicos, pero los de estado van más ligados a la identidad del objeto y su funcionamiento general.
- Componentes: estos campos contienen propiedades del objeto en cuestión que no buscan ser como los estratégicos.
- Parámetro: es la forma de comunicar a un objeto con otro si no se tienen un campo del objeto en cuestión declarado. Mediante un método un objeto recibe información de otro objeto o el objeto en si.
- Recopiladores: son pasados con el fin de ir añadiendo información en él.
- Opcionales: Como cuando tenemos diferentes constructores que reciben distintos número de parámetros, con el fin de pasar solo los datos que queramos o todos.
- Argumentos variables: Para poder pasar parámetros sin un número determinado de ellos, ya sea mediante una colección, o delegando a la función que cree una colección a partir de todo lo que se le pasa (Class… classes).
- Objeto: cuando se pasa un objeto como parámetro con el fin de reusar código en la lógica.
- Constantes: Datos que son accedidos en muchos sitios, pero que no cambian. Al declararlo así nos aseguramos que la variable está protegida ya que nunca debería cambiar. Por convención debería escribirse su nombre en mayúsculas.
- Nombres de acuerdo a un rol: Definir las variables según el rol/función que vayan a cumplir. result → si guarda el objeto que retorna una función for(Person person: people) → llamamos a la variable “person” porque la lista “people” tiene un conjunto de “person”. count → guarda la cuenta de algo. etc…
COMPORTAMIENTO
Se describen una serie de patrones sobre como expresar el comportamiento de un programa:
- Flujo de control: Expresa los cálculos como una secuencia de pasos. Java es un miembro de la familia de lenguajes en los que la secuencia de control es un principio organizativo fundamental. Las declaraciones adyacentes se ejecutan una detrás de otra. Los condicionales, bucles, excepciones, etc, definen el flujo a seguir del programa. Teniendo ésto claro podemos decir que cada paso cuenta a la hora de tener un buen producto.
- Flujo principal: Los programadores generalmente tienen en mente un flujo principal de control para sus programas. El procesamiento comienza aquí y termina allí. Puede haber decisiones y excepciones a lo largo el camino, pero el cómputo tiene un camino a seguir. Pensar desde donde y hacía donde queremos llegar, sumará a la hora de tener una mejor idea de como implementar funcionalidad.
- Mensaje: La programación orientada a objetos enriquece el mensaje que transmitimos, ya que para una secuencia de instrucciones se define un mensaje (método) que abstrae al lector de conocer todos los detalles del funcionamiento, solo necesita aplicar la lógica común. No solo importa a la hora de leerlo, si no que será un factor fundamental a la hora de poder ampliar el comportamiento actual del programa.
- Eligiendo el mensaje: Debemos tener cuidado con el nombre que elijamos para el mensaje que queremos transmitir, ya que un mal nombre hará una mala representación de la lógica que estamos abstrayendo. Nombres que sean el resumen o el factor clave de lo que hace la lógica.
- Mensaje descompuesto: Cuando se tiene una serie de algoritmos complicados, podemos usar un nombre que descomponga cada tarea que cumpla el algoritmo y concatene cada una de ellas para formar un nombre descriptivo que permita al lector ignorar los detalles de implementación.
6. Mensaje de reversión: No solo importa que sea un buen mensaje, además debería estar al mismo nivel de abstración que los demás mensajes de su ámbito, por lo que si nuestro mensaje es más complicado que otros mensaje que le proceden o preceden, deberíamos buscar la forma de que queden al mismo nivel abstración.
void compute() {
input();
helper.process(**this**);
output();}
*/******************************************/*
compute() {
**new** Helper(**this**).compute();
}
Helper.compute() {
input();
process();
output();
}
- Mensaje de invitación: Cuando queremos transmitir el mensaje de que una clase es solo una idea de funcionamiento y que requiere de especificaciones o subclases, indicamos que la clase es abstracta, por lo que no se puede instanciar, solo mejorar.
- Mensaje explicativo: Transmitir la intención de la lógica en el mensaje mediante un comentario o el nombre de un método.
- Flujo excepcional: Si es cierto que un programa siempre tienen un flujo principal, son las clausulas guardas o las excepciones las que crear un flujo alternativo.
- Clausula guarda: Son condiciones que harán que nuestro método de un salto, ignorando la lógica que venga después, ya que con ésto damos a entender que se ha dado una condición en la que no necesitamos seguir operando.
- Excepciones: Son condiciones que expresan que no se puede implementar cierta lógica pensada debido a algún fallo en la computación. Podemos crear nuestras propias excepciones para aportar mayor expresividad al código, y así poder manejar mejor éstas excepciones. Con manejar las excepciones nos referimos a recuperarnos del fallo de tal manera que si un bloque de código no se puede ejecutar, hay otro que tomará el relevo y que coge como contexto el fallo obtenido que provocó la excepción. Además, tener nuestra propia excepción, nos da un mayor feedback de porqué falla el código.
MÉTODOS
Nuestros programas pueden tener una lógica muy variante, ya que vamos desarrollando un bloque de código por función que el programa final deba tener. Perfectamente, toda la lógica podría contenerse en un solo método, pero para eso usamos métodos, para cumplir una tarea específica, evitando tener que un método cumpla más de una tarea. Los beneficios son claros, la legibilidad obtenida al separar la lógica en métodos es un gran punto a favor, pero además entra en juego la expresividad, ya que así distinguimos partes más importantes o menos importantes.
Lo mejor de los métodos es que se entienden por separado, abstraen al lector de tener que leer otras implementaciones que no son necesarias para entender la tarea que está cumpliendo un método. Evitan la repitición de código, ya que varias llamadas a un método equivale a ejecutar tantas veces un bloque de código sin tener que haberlo escrito más que una vez para crear el método.
Que nos aporten tantos beneficios no quiere decir que no puedan suponer una desventaja, ya que se debe cuidar su tamaño, nombre y propósito. Si haces demasiados métodos muy pequeños, los lectores tendrán dificultades para seguir su fragmentada expresión de ideas. Pocos métodos conducen a la duplicación y a la consiguiente pérdida de flexibilidad.
A continuación se definen una serie de patrones relacionados con los métodos:
MÉTODOS COMPUESTOS
Cuando se componen métodos a partir de llamadas a otros métodos, cada uno debe tener el mismo nivel de abstracción.
void compute() {
input();
flags|= 0x0080; /*FIX: flags();*/
output();
}
Una objeción al uso de muchos pequeños métodos es la penalización por rendimiento impuesta por la invocación de todos esos métodos.
Se suele recomendar desarrollar métodos estableciendo un límite de líneas de código que ronde entre 5 y 15. Aunque hay que tener en cuenta que no se debe sacrificar la legibilidad o expresividad por la longitud estándar de los métodos, ya que por ejemplo un simple espacio en blanco puede llegar a aportar mucho si separa dos estructuras de distinas complejididades, nos aporta expresividad. Un método se convierte en un obstáculo cuando me dedico a tratar de entender el código en detalle.
El truco para elaborar un método está en reconocer cuando tengo conjuntos de detalles relativamente independientes que pueden ser movidos a métodos de apoyo.
REVELAR LA INTENCIÓN EN EL NOMBRE DEL MÉTODO
Los métodos deben ser nombrados con el propósito de que un posible invocador pueda tener en mente porqué usa ese método. Nombre métodos para que ayuden a contar la historia.
VISIBILIDAD DEL MÉTODO
Los cuatro niveles de visibilidad -public, package, protected, private- cada uno dice algo diferente sobre sus intenciones para un método. Si no necesitamos que otros sitios conozcan un método, la mejor manera de expresarlo es declararlo private. En cuanto a la flexibilidad, debemos tener en cuenta que cuantos más métodos privados tengamos más fácil sera escalar, ya que no existe código más allá del de la propia clase que depende de él, pero si a raiz de ésto dificultamos demasiado que otras clases que lo necesiten puedan acceder al método, lo mejor sería declarar como tipo public, debemos encontrar en balance para cada situación.
- Public → Accesible en cualquier paquete o clase. Hacer un método público significa que aceptas la responsabilidad de mantenerlo, ya sea dejándolo sin cambios, o arreglando todas las llamadas si cambia.
- Protected → Sólo las clases que hereden de la superclase, podrán acceder a métodos declarados así.
- Private → Sólo será accesible en la misma clase o paquete. Nos aporta una flexibilidad, ya que el cambio se realizará solo en éste punto y no tendremos que realizarlo en múltiples sitios como lo haríamos como un método público.
Revelar lentamente los métodos, comenzando con la visibilidad más restrictiva que trabajar y revelarlos cuando sea necesario. Si un método ya no necesita ser visible, reducir su visibilidad. Declarar los métodos finales es similar a elegir su visibilidad. Declarar un método final establece que aunque no te importa que la gente use este método, tú no permitirás que nadie lo cambie, nos da la seguridad de que nadie romperá accidentalmente el objeto ya que su valor es invariante. Declarar un método estático lo hace visible incluso si la persona que llama no tiene el acceso a una instancia de la clase. Los métodos estáticos están limitados en el sentido de que no pueden depender de ninguna instancia por lo que no son un buen depósito para la lógica compleja. El buen uso de los métodos estáticos es como un reemplazo para los constructores.
OBJETO DE MÉTODO
Para crear un objeto de método, busque un método largo con muchos parámetros y variables temporales. Tratar de extraer cualquier parte del método resultaría en largas listas de parámetros en submétodos difíciles de nombrar.
- Crear una clase con el nombre del método. Por ejemplo,
complexCalculation()se convierte enComplexCalculator. - Crear un campo en la nueva clase para cada parámetro, variable local y campo utilizado en el método. Dale a estos campos los mismos nombres que tienen en elmétodo original.
- Crear un constructor que tome como parámetros los parámetros del método de la método original y los campos del objeto original utilizados por el método.
- Copie el método en un nuevo método,
calculate(), en la nueva clase. - Sustituir el cuerpo del método original por un código que cree una instancia de la nueva clase. Por ejemplo:
complexCalculation() {
new ComplexCalculator().calculate();
}
- Si los campos fueron establecidos en el método original, establézcalos después de los retornos del método:
complexCalculation() {
ComplexCalculator calculator = new ComplexCalculator();
calculator.calculate();
mean = calculator.mean;
variance = calculator.variance;
}
Asegúrate de que el código refactorizado funcione como el antiguo código. El código de la nueva clase es fácil de refactorizar. Puedes extraer métodos y no tener que pasar nunca ningún parámetro porque todos los datos utilizados por el método se almacenan en campos. A menudo, una vez que se empiezan a extraer los métodos se descubre que algunas variables pueden ser degradadas de los campos a los locales.
MÉTODO ANULADO O SOBRESCRITO
Los métodos anulados son una forma clara de expresar una variación. Los métodos declarados abstractos en un superclase son una clara invitación a especializar un cálculo, pero cualquier método no declarado final es un candidato para expresar una variación en un cálculo existente. Los métodos bien compuestos en la superclase proporcionan una multitud de potenciales ganchos en los que puedes colgar tu propio código. Si el código de la superclase está en pequeños trozos cohesivos, entonces serás capaz de anular métodos enteros. Anular un método no es ninguna de las dos cosas. Puedes ejecutar el código de la subclase y el código de la superclase invocando super.method(); para invocar el método del mismo nombre.
MÉTODO SOBRECARGADO
Cuando declaras el mismo método con diferentes tipos de parámetros, dices “Aquí hay formatos alternativos para los parámetros de este método”. Los métodos sobrecargados alivian al llamante de la responsabilidad de convertir los parámetros si hay varias formas legítimas de pasando los parámetros. Una variante de la sobrecarga es usar el mismo nombre de método con diferentes número de parámetros. El problema con este estilo de sobrecarga es que los lectores que quieran preguntar: “¿Qué pasa cuando invoco este método?” necesitan leer no sólo el nombre del método sino también la lista de parámetros antes de que saber lo suficiente para averiguar lo que sucede como resultado de la invocación del método. Si la sobrecarga es complicada, los lectores necesitan entender la sutil sobrecarga reglas de resolución para poder determinar estáticamente qué método se invocará para determinados tipos de argumentos. Los métodos sobrecargados deben servir todos para el mismo propósito, con la variación sólo en los tipos de parámetros. Diferentes tipos de retorno para diferentes sobrecarga dos los métodos hacen que la lectura del código sea demasiado difícil. Es mejor encontrar un nuevo nombre para la nueva intención. Darle a los diferentes cálculos diferentes nombres.
MÉTODO DE RETORNO
El tipo de retorno de un método señala primero si el método es un procedimiento que funciona por efecto secundario o una función que devuelve un tipo de objeto particular. El tipo de retorno void permite distinguir entre procedimientos y funciones.A veces tu intención es que el tipo de retorno sea específico, un tipo de objeto concretoo uno de los tipos primitivos. Sin embargo, le gustaría que sus métodos fueran tan lo más ampliamente posible, así que elige el tipo de retorno más abstracto que expresa su intención. Esto conserva la flexibilidad para que puedas cambiar la tipo de retorno concreto en caso de que sea necesario en el futuro. Generalizar el tipo de retorno también puede ser una forma de ocultar detalles de la implementación. Por ejemplo, la devolución de una colección en lugar deunalista puede animar a los usuarios a no asumir que los elementos están en un orden fijo.
MÉTODO DE COMENTARIO
Expresar la mayor cantidad de información posible a través de los nombres y la estructura de el código. Añade comentarios solo para expresar decisiones e información que no es obvia del código.Las pruebas automatizadas pueden comunicar información que no encaja de forma natural en comentarios de método. Automatizado las pruebas tienen muchas ventajas. Escribirlas es un valioso ejercicio de diseño, especialmente cuando se hace antes de la aplicación. Si las pruebas se realizan, son consistentes con el código. Las herramientas de refactorización automatizada pueden ayudar a mantener las pruebas actualizadas a un nivel bajo costo.
MÉTODO DE AYUDA
Grandes métodos convertidos en varios más pequeños, los denominamos ‘helpers’ son los ayudantes. Su propósito es hacer que los cálculos de mayor complejidad sean más leídos ocultar detalles irrelevantes y darle la oportunidad de expresar su intención a través del nombre del método.Los ayudantes son típicamente declarados private, pasando a protected si la clase está destinada a ser refinada por subclasificación. Son éstos helpers los que llama otro método que si sea accesible para otras clases, o puede que quizas solo sirvan para apoyar a otro método private de la clase.
MÉTODO PARA PRUEBA CON IMPRESION
Son métodos que definimos sin más funcionalidad que mostrar cierta información útil sobre un objeto, como puede ser untoString();para imprimir información sobre propiedades que sirva de debug de la aplicación entre otras cosas.
COLECCIONES
El comportamiento de colección solía ser implementado proporcionando enlaces en la estructura de datos en sí misma: cada página de un documento tendría enlaces con la anterior y las siguientes páginas. Más recientemente, la moda ha cambiado a usar un objeto separado para la colección que relaciona los elementos. Esto permite la flexibilidad de poner el mismo objeto en varias colecciones diferentes sin modificar el objeto.
Metáfora
Las colecciones mezclan diferentes metáforas. La primera es la de una variable de valor múltiple, una variable que se refiere a una colección es en realidad una variable que se refiere a varios objetos al mismo tiempo, pero dicha variable no se considera un objeto. Como con todas las variables, puede asignar a una variable de valor múltiple (añadir y quitar elementos), recuperar su valor, y enviar los mensajes variables (con el bucle for). La metáfora de la variable multivaluada se rompe en Java porque las colecciones son objetos separados con identidad. La segunda metáfora mezclada en las colecciones es la de los objetos - una colección es un objeto. Puedes recuperar una colección, pasarla alrededor, probarlo para la igualdad, y enviarle mensajes. Así que, así como las colecciones son variables de múltiples valores, también son objetos. Otra metáfora útil es pensar en las colecciones como conjuntos matemáticos. Una colección divide el mundo de los objetos en objetos que están en la colección y los objetos que no lo son. Dos operaciones básicas en los conjuntos matemáticos están encontrando su cardinalidad (el método size() de las colecciones) y probando la inclusión (representada por el método contains()).
Conceptos
El primer concepto expresado por las colecciones es su tamaño. Los Arrays (que son colecciones primitivas) tienen un tamaño fijo, establecido cuando se crea el conjunto. La mayoría las colecciones pueden cambiar de tamaño después de ser creadas. Un segundo concepto expresado a través de las colecciones es si el orden de elementos es importante. El orden puede ser el orden en que los elementos se añadieron o puede ser proporcionada por alguna influencia externa como la lexicográfica comparación. Por último, las consideraciones sobre el rendimiento se comunican mediante la elección de colección. Si una búsqueda lineal es lo suficientemente rápida, una colección genérica es lo suficientemente buena. Si la colección crece demasiado grande, será importante poder probar o acceder elementos por una clave, sugiriendo un conjunto o mapa.
Interfaces
La declaración de la interfaz dice al lector sobre la colección: si la colección está en un orden particular, si hay elementos duplicados, y si hay alguna manera de buscar elementos por clave o sólo por iteración. Los tipos de interfaces para colecciones se describen a continuación:
Arrays: Desafortunadamente, no tienen el mismo protocolo que otras colecciones, por lo que es más difícil cambiar de un array a una colección que de un tipo de colección a otro. A diferencia de la mayoría de las colecciones, el tamaño de un conjunto se fija cuando se crea. Los arrays son más eficientes en el tiempo y el espacio que otras colecciones de simples operaciones. El acceso que tienen los arrays (es decir, elementos[i]) es más de diez veces más rápido que el equivalente de ArrayList (elements.get(i)).
Iterable: Declarar una variable Iterable sólo dice que contiene múltiples valores. Iterable es la base para la construcción del bucle en Java 5. Cualquier objeto declarado como Iterable puede ser usado en un bucle. Esto se implementa llamando tranquilamente al método iterator(). Una de las cuestiones que hay que comunicar al utilizar las colecciones es si se espera que los clientes los modifiquen. Desafortunadamente, Iterable y su ayudante, Iterator, no proporcionan ninguna manera de declarar que una colección no debe ser modificada. Una vez que tienes un Iterator, puedes invocar su método remove(), que elimina un elemento del Iterable subyacente.
Collection: La colección hereda de Iterable, pero añade métodos para añadir, eliminar, buscar y contar los elementos. Declarar una variable o método como una colección deja muchas opciones para una clase de implementación. Dejando la declaración tan vagamente especificada como sea posible, usted mantiene la libertad de cambiar las clases de implementación más tarde sin que el cambio se extienda a través del código.
List: A la colección, la lista añade la idea de que los elementos están en un orden estable. Un elemento puede ser recuperado proporcionando su índice a la colección. Una secuencia estable es importante cuando los elementos de una colección interactúan entre sí.Set: Un conjunto es una colección que no contiene duplicados (elementos que informarían que son iguales() entre sí).
SortedSet(conjunto ordenado): SortedSet almacena elementos ordenados pero únicos. A diferencia del orden de una Lista, que está relacionado con el orden en que los elementos fueron añadidos o por índices explícitos pasados a add(int, Object), el ordenamiento en un SortedSet es proporcionado por un Comparador. En ausencia de un orden explícito, se utiliza el “orden natural” de los elementos. Por ejemplo, los Strings se clasifican en orden lexicográfico.
Map: La última interfaz de recolección es Map, que es un híbrido de las otras interfaces. El mapa almacena los valores por clave, pero a diferencia de una lista, la clave puede ser cualquier objeto y no sólo un número entero. Las claves de un mapa deben ser únicas, aunque los valores puede contener duplicados. Los elementos de un Mapa no están en ningún orden particular. Debido a que Map no es completamente como cualquiera de las otras interfaces de la colección, se encuentra sola, sin heredar de ninguno de ellos. Los mapas son dos colecciones en el al mismo tiempo; una colección de llaves conectadas a una colección de valores.
Implementaciones
Collection
La clase predeterminada es ArrayList, pero ésta puede no darnos el resultado esperado al realizar un contains(object) o un remove(object), ya que en éste tipo se permiten duplicados y solo borrará el primer resultado encontrado. Lo más seguro y eficaz es usar en su lugar HashSet.
List
Añade la idea de que los elementos están en un estable orden. Las dos implementaciones de la Lista de uso común son ArrayList y LinkedList. ArrayList es rápido para acceder a los elementos y lento para añadir y quitar elementos, mientras que LinkedList es lento para acceder a los elementos y rápido para añadir y eliminar elementos.
Set
Hay tres implementaciones principales de Set: HashSet, LinkedHashSet, y TreeSet (querealmente implementa SortedSet). HashSet es el más rápido pero sus elementos no están en orden garantizado. Un LinkedHashSet mantiene los elementos en el orden en que fueronañadió, pero a costa de una penalización extra del 30% de tiempo por añadir y quitarelementos. TreeSet mantiene sus elementos ordenados de acuerdo a un comparadorpero a costa de hacer que la adición y la eliminación de elementos o la prueba de un elemento lleve un tiempo proporcional a n, donde n es el tamaño de la colección.
Map
Las implementaciones de Map siguen un patrón similar a las implementaciones deSet. HashMap es el más rápido y simple. LinkedHashMap preserva el orden de los elementos,iterando sobre los elementos en el orden en que fueron insertados. TreeMap (en realidad una implementación de SortedMap) itera sobre las entradas basadas en el orden delclaves.
Clase Collections
Búsqueda
La operación indexOf() toma un tiempo proporcional al tamaño de la lista. Llama a Collections.binarySearch(list, element) para devolver el índice de un elemento en ellista. Si el elemento no aparece en la lista, se devolverá un número negativo.
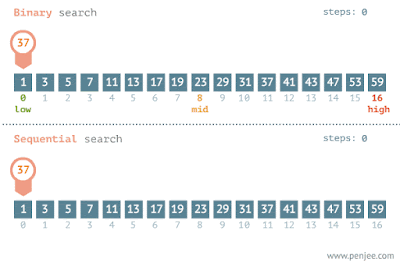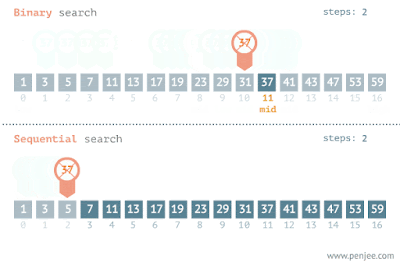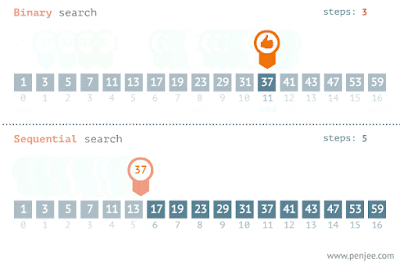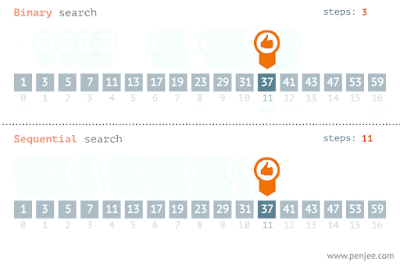
Ordenar
Las colecciones también proporcionan operaciones para cambiar el orden de los elementos de una lista. Reverse(list) invierte el orden de todos los elementos de la lista. Shuffle(list) coloca los elementos en orden aleatorio. Sort(list) y Sort(list, comparator) coloca los elementos enen orden ascendente.
DESARROLLO DE FRAMEWORKS
En éste capítulo, se habla de como cambian los patrones de implementación, cuando el fin es desarrollar un framework.
CAMBIAR LOS FRAMEWORKS SIN AFECTAR A LAS APLICACIONES
El dilema fundamental en el desarrollo y mantenimiento de los frameworks es que necesitan evolucionar, pero hay un gran costo por romper el código de cliente existente. La actualización del framework perfecta, añade nuevas funciones sin cambiar ninguna de las existentes, aunque éstas actualizaciones compatibles no siempre son posibles.Cuando desarrollamos un framework la mentalidad debe ser totalmente distinta que cuando realizamos código de producto convencional, ya que con una herramienta de éste tipo, se debe tener en cuenta que en algunas ocasiones es preferible un bloque de código más complejo, pero que es mucho más mantenible y mejorable, sin romper código de cliente. A pesar de ésto, la simplicidad siempre debe estar presente, y considerada siempre que sea posible.
ACTUALIZACIONES INCOMPATIBLES
Una actualización que se descompone en pasos más pequeños, avisa al cliente de que es lo nuevo que viene y el por qué debe actualizarse a la nueva API. Un ejemplo de esto son los métodos deprecados, funcionan pero avisan de que se espera eliminar en futuras versiones. Los paquetes pueden proporcionar una forma de ofrecer a los clientes un acceso incremental a las actualizaciones. Introduciendo nuevas clases en un nuevo paquete, puedes darles el mismo nombre como las viejas clases. Por ejemplo, si puedo actualizar org.junit.Assert en org.junit.newandimproved.Assert , entonces los clientes sólo tienen que cambiar las declaraciones de importación para usar el nueva clase. Cambiar las importaciones es menos arriesgado e intrusivo que cambiar el código. Otra estrategia incremental es cambiar la API o la implementación, pero no ambas en la misma versión. Ésta versión intermedia, asociaría la nueva interfaz con el viejo código, o la vieja interfaz con el nuevo código, lo que daría más tiempo para afrontar y adaptarse al cambio. IDEs como Eclipse, ofrecen herramientas automatizadas para actualizar el código de cliente, de tal forma que añade archivos y mueve funcionalidad, con el fin de adaptarse a la nueva versión. Puedes reducir el costo de cambiar el código si los clientes pueden cambiar a tu funcionalidad mejorada con una simple operación de búsqueda/reemplazo. El cambio del nombre de un método, será más barato para los clientes si dejas los argumentos en el el mismo orden.
FORMATEANDO UN CAMBIO COMPATIBLE
Lo ideal sería que el código de cliente depende lo menor posible del framework, y cuando esto no sea posible (para eso está el framework), se debe intentar que la funcionalidad de la que dependa no sea propensa a cambios, algo que se consigue mediante reducir el número de detalles visibles y mostrar detalles reveladores que son menos probables de cambiar y entregar funcionalidad útil, mientras se mantiene la libertad de cambiar el diseño.
CLASE LIBRERIA
Un estilo simple y que considera bastante el futuro de la API es la clase de biblioteca. Representan toda su funcionalidad como llamadas de procedimiento con parámetros simples, entonces los clientes están bien aislados de futuros cambios. Cuando liberas un nuevo de su clase de biblioteca sólo necesita asegurarse de que todos los métodos existentes trabajan igual que antes. La nueva funcionalidad se representa como nueva o nuevas variantes de los procedimientos existentes. La clase Colecciones es un ejemplo de una API representada como una clase de biblioteca. Los clientes la utilizan invocando métodos estáticos, no instanciándola. Nuevas versiones de las clases de colección añaden nuevos métodos estáticos, dejando a los existentes funcionalidad sin cambios.
OBJETOS
Asumiendo que vamos a representar nuestro framework como objeto, existe una tarea más dura que equilibra la simplicidad y la complejidad, la flexibilidad y la especificidad, así que el framework debe ser a la vez útil que útil, estable para los clientes y evolutivo para usted. El truco es, en la medida que puedas manejarlo, escribir el framework para que los clientes dependen sólo de detalles que no es probable que cambien.
ESTILO DE USO
Los frameworks pueden soportar tres estilos principales de uso: instanciación, configuración,e implementación. Cada estilo ofrece diferentes combinaciones de usabilidad, flexibilidad y estabilidad. También puedes mezclar estos estilos en un solo frameworks para proveer un mejor equilibrio entre la libertad de diseño para los desarrolladores y el poder para los clientes. El estilo más simple de uso es la instanciación. Cuando quiero un socket de servidor escribo:
new ServerSocket()
Una vez instanciado, funciona invocando métodos en él. La instanciación funciona cuando la única forma de variación que los clientes necesitan es la variación de los datos, no la lógica. La configuración es un estilo de uso más complejo y flexible en el que el cliente crea objetos usando el framework, pero les pasa sus propios objetos para ser llamados en tiempos determinados. Un TreeSet , por ejemplo, puede ser llamado con un Comparator para permitir una clasificación arbitraria de los elementos. La configuración es más flexible que la instanciación porque puede acomodar las variaciones en la lógica así como en los datos. Sin embargo, ofrece menos libertad al programador, porque una vez que empiezas a llamar a un objeto del cliente, surge la necesidad de seguir llamando a ese objeto de la misma manera y al mismo tiempo o arriesgarse a romper el código del cliente. Cuando los clientes necesitan más formas de enganchar su propia lógica que las proporcionadas por configuración, entonces puede ofrecer el uso por implementación. En la implementación,los clientes crean sus propias clases que son utilizadas por el framework. Siempre y cuando la clase de cliente extienda de una clase del framework o implemente una interfaz, el cliente es libre de incluir cualquier lógica que le guste. JUnit mezcla los cuatro estilos de uso:
JUnitCore es una clase de biblioteca con un método de ejecución estática(Class…) para ejecutar todas las pruebas en todas las clases. JUnitCore es también instancial, con instancias que proporcionan un control más fino sobre la prueba ejecutando y notificando. Las anotaciones @Test , @Before y @After son una forma de configuración donde la prueba los escritores pueden identificar bits de código para ser ejecutados en ciertos momentos. La anotación @RunWith es una forma de implementación, donde los escritores de pruebas que necesitan un comportamiento de prueba no estándar pueden implementar sus propios corredores.
ABSTRACCIÓN
Sobre que forma es mejor para implementar el framework, introduce la cuestión de si representar las entidades abstractas como una interfaz o una superclase común. Cada enfoque tiene ventajas y desventajas para los desarrolladores y clientes. Los dos enfoques tampoco son mutuamente excluyentes. Un framework puede ofrecer a los clientes tanto una interfaz como una implementación predeterminada de esa interfaz.
INTERFAZ
La gran ventaja de ofrecer a los clientes una interfaz es que las interfaces registran pocos detalles. Los clientes no pueden usar “accidentalmente” más del framework de lo previsto. Sin embargo, esta protección tiene un costo. Mientras las interfaces permanezcan sin cambios están bien, pero introducir un nuevo método en una interfaz rompen todas las implementaciones cliente de esa interfaz. Una variación de las interfaces que proporciona cierta flexibilidad adicional a costa de cierta complejidad son las interfaces versionadas. Si se añaden operaciones a un interfaz, rompes el código del cliente. Sin embargo, puedes crear una subinterfaz y poner las nuevas operaciones allí. Los clientes pueden pasar objetos que se ajusten a la nueva donde se espera la antigua interfaz, pero el código existente continúa trabajando como antes.
SUPERCLASE
Las ventajas de este estilo son las inversas a las de las interfaces: las clases pueden especificar más detalles que las interfaces, pero añadir una operación a una superclase no rompe el código existente. A diferencia de las interfaces, con la superclases, las clases de cliente sólo pueden extender una clase del framework. Reducir el máximo el numero de detalles visibles para el cliente, nos garantiza una menor limitación en un cambio de diseño futuro. Los campos en un framework siempre deben ser privados. Si los clientes necesitan acceso a los datos de los campos, facilítenlo a través de getters. Examine cuidadosamente sus métodos y haga públicos sólo los métodos esenciales o, mejor aún, protegido. Seguir estas reglas permite definir una superclase que expone sólo unos pocos detalles más que la interfaz equivalente pero permite los clientes más flexibilidad para engancharse a su propia lógica. La palabra clave abstract te da una forma de comunicarte con los clientes donde ellos se requieren para llenar la lógica. Proporcionar una aplicación razonable por defecto de métodos donde sea posible para los clientes la posibilidad de empezar fácilmente. La palabra clave final cuando se aplica a una clase evita que los clientes creen subclases, reforzando la instanciación o el estilo de configuración del uso del framework. Los marcos que se organizan en varios paquetes necesitan una declaración de visibilidad que diga, “Visible dentro del marco pero no a los clientes”. Una solución a este problema es separar los paquetes en publico e interno y comunicar la diferencia incluyendo al nombre “internal” en las rutas de paquetes internos. Los paquetes internos proporcionan un punto intermedio entre revelar y ocultar detalles del marco. Los clientes pueden elegir por sí mismos cuánta responsabilidad quieren aceptar para construir encima de partes potencialmente inestables del framework.
SIN CREACIÓN
La opción más simple y menos poderosa es prohibir a los clientes crear los objetos de la estructura directamente. Los operadores en un método de factoría pueden garantizar que los eventos están bien formados. La limitación de no permitir que los clientes creen instancias de marco es que impide los usos legítimos de las clases.
MÉTODO ESTÁTICO (FACTORÍA)
Añaden cierta complejidad a la creación de objetos para los clientes, pero dejan al desarrollador más libertad para futuros cambios de diseño. Si un cliente creó una lista diciendo ArrayList.create() en lugar de usar un constructor, entonces la clase concreta del objeto devuelto podría ser cambiada sin que afecta al código de cliente. Otra ventaja de las factorías estáticas es que te dan la oportunidad de comunicar claramente a los clientes el significado de las variaciones en la construcción.
OBJETO DE MÉTODOS ESTÁTICOS (FACTORÍA)
También puedes representar la creación de instancias enviando mensajes a una fábrica en lugar de invocar un método estático. Por ejemplo, un CollectionFactory podría proporcionan métodos para crear todos los diferentes tipos de colecciones. Podría ser usado así:
Collections.factory().createArrayList()
Un objeto de fábrica proporciona incluso más flexibilidad que una método estático pero es más complejo de leer. Necesitas rastrear la ejecución del código para ver cuando se crean ciertas clases. Mientras la fábrica sólo se acceda globalmente, un objeto de fábrica no proporcionan más flexibilidad que los métodos de fábrica estáticos.